Databricks used a May 27, 2026 blog post to introduce Lakebase Change Data Feed, or CDF, in Public Preview, positioning it as a simpler way to expose operational database changes without building a separate extraction layer for every downstream destination. The company says teams can enable CDF once per Lakebase project and expose changes from every table through Unity Catalog Managed Tables, where the feed can be stored, governed, and read directly by any engine, model, or agent. That pitch is aimed at a broad set of consumers across OLTP systems, the lakehouse, BI workloads, and agentic applications. In practical terms, Databricks is presenting Lakebase CDF as a native project wide CDC mechanism that is supposed to reduce the pipeline sprawl that often follows operational data once it needs to travel beyond the primary database. Source
A familiar CDC pain point, restated
The problem statement in the announcement is familiar, but Databricks states it bluntly. Moving data out of an operational database, it argues, still means setting up and monitoring a pipeline for each source and each destination, which creates a brittle and ungoverned pattern that becomes O(n) human effort. The post also ties that pain to newer development patterns, saying the branching complexity of agent first workflows makes the old model even less sustainable. In the vendor's description, teams end up managing database connectors, watching replication state, running separate extraction jobs, and troubleshooting failures across disconnected tools. Lakebase CDF is presented as the alternative: native CDC governed end to end, without sidecar infrastructure, so downstream systems subscribe to one managed feed instead of multiplying bespoke copies of the same operational changes. Source
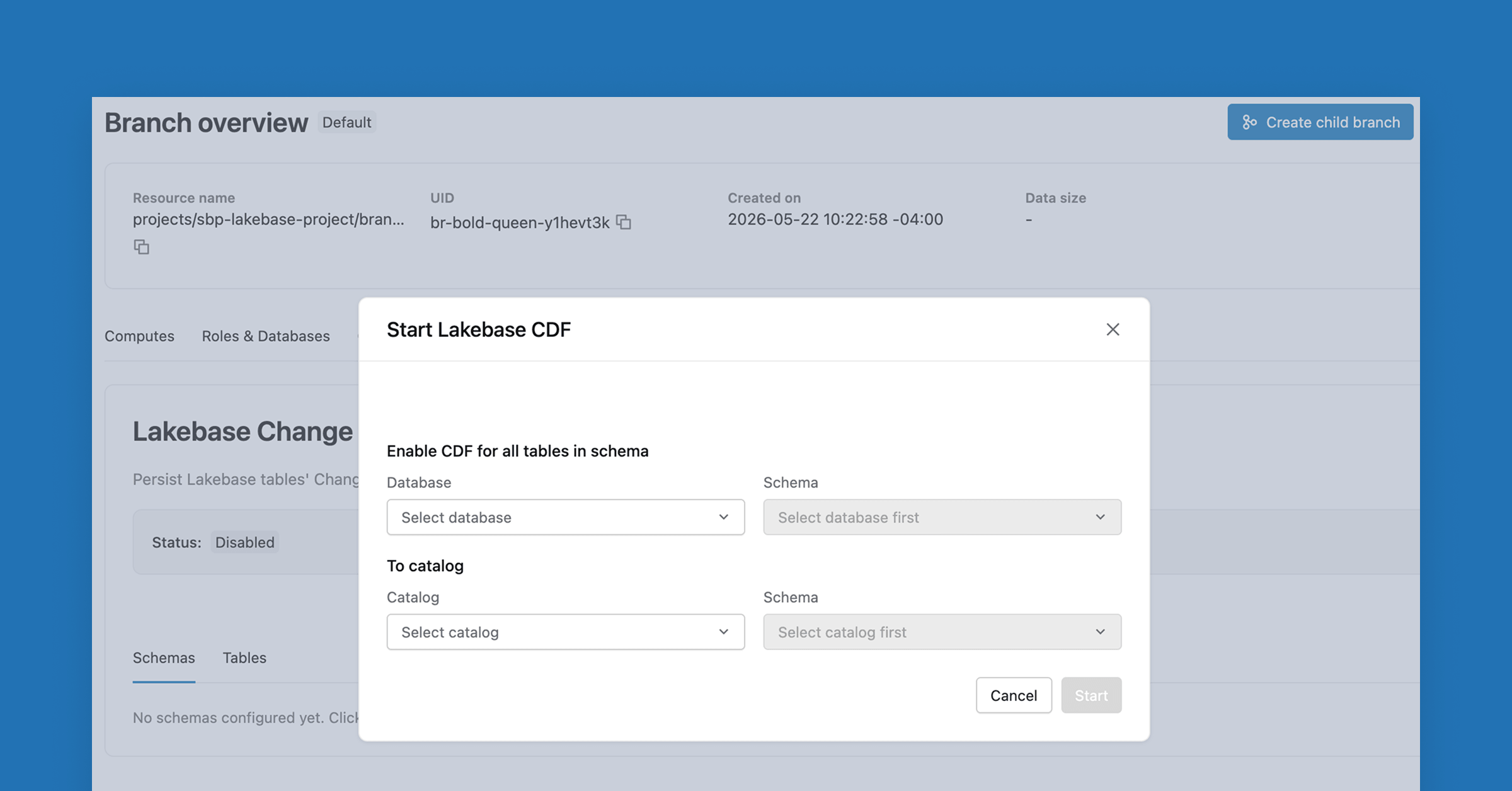
Mechanically, Databricks says the feature takes less than a minute to enable and that the setting applies to all tables within a Lakebase project. That matters because the scope is not a per table toggle or a per consumer export. Once enabled, every downstream consumer is supposed to subscribe to the exact same feed, while remaining completely isolated from the primary operational workload. Databricks also emphasizes that the feed lives in Unity Catalog Managed Tables, which gives the company a way to frame CDF as both a movement and governance feature rather than a connector alone. The practical promise is straightforward: enable the feed once, let every engine, model, and agent read from it directly, and remove the need for separate landing jobs just to make transactional changes available elsewhere. Source
One feed for pipelines, BI, and AI
Databricks uses a few concrete examples to show how that common feed could be consumed. The blog points to SDP streaming pipelines, DBSQL materialized views, and Agent Bricks embeddings as downstream subscribers, all reading from the same isolated source rather than from their own extraction path. That is a notable framing because it pulls classical data engineering, BI refresh, and AI enrichment into one CDC story. Instead of treating operational data as something that must be copied and reshaped through a long chain before it becomes useful, Databricks is trying to make the feed itself the reusable system boundary. For readers following the broader convergence of data platforms and AI tooling, this is the part that connects Lakebase most clearly to the wider Databricks stack. our recent Snowflake Iceberg write support coverage Source
Lakebase as the Bronze entry point
The architectural claim underneath the launch is arguably the bigger story. Databricks says operational data can now function as the native Bronze layer in the medallion architecture, eliminating the need for separate pipelines or extraction jobs to land that data in the Lakehouse. The company adds that Lakebase Synced Tables already serve Gold data to applications, and frames CDF as the missing link that closes the loop with full Unity Catalog governance and lineage across the data lifecycle. In other words, Databricks is not pitching this as a narrow CDC utility. It is positioning Lakebase as part of the same managed data continuum that analytics teams already associate with the Lakehouse. The post explicitly draws a parallel to the way the Lakehouse simplified extraction by storing data once in open formats such as Delta Lake and Apache Iceberg and using CDF as a downstream replication standard for ETL, streaming workflows, and audit logs. Source
What this could remove from the data platform backlog
For CTOs and VPEs, we think the operator level appeal here is less about a new acronym and more about a tighter control plane. If the product behaves as described, the important shift is that enablement is project wide, governance sits in Unity Catalog Managed Tables, and downstream subscribers are isolated from the primary OLTP workload. That combination could reduce the number of moving parts platform teams need to own across connectors, replication monitoring, and separate extraction jobs. We would read the main evaluation question as operational rather than conceptual: how completely can one governed feed replace the current mix of custom CDC paths for streaming, BI, and AI consumers? Databricks is clearly arguing that the answer should be one feed for all tables in a project, with one governance model, instead of many pipelines maintained by hand. Source
The language around engines, models, and agents also matters because it shows where Databricks thinks CDC is headed. The blog does not stop at database replication or analytical reporting. By naming direct read access for agents and citing Agent Bricks embeddings as a downstream pattern, Databricks is placing change data inside the operational backbone of AI applications as well. At the same time, the company keeps returning to governance, isolation, and shared access, which suggests it wants to avoid the usual tradeoff where broader availability means weaker control. That is consistent with the announcement's closing note that this is just the start and that Databricks is bringing the openness users associate with the Lakehouse directly to Lakebase. The message is not only about moving data faster, but about keeping one managed path as the number of consumers expands. Source
As announced, Lakebase CDF remains a Public Preview feature, so the launch is more about architecture and intent than broad proof points. Still, the outline is specific. Databricks says teams can turn on change capture once per Lakebase project, expose changes for every table, store and govern those changes through Unity Catalog Managed Tables, and let any engine, model, or agent read from the resulting feed without affecting the primary workload. That creates a clean headline for Databricks to take to customers already standardizing on its platform: enable CDC once, then govern it everywhere across operational systems, the lakehouse, BI layers, and emerging agent experiences. If Lakebase CDF delivers on that promise, Databricks will have moved operational databases closer to the same governed, reusable data lifecycle it has long argued for on the analytics side. Source