Databricks published a 39 minute read on June 3 titled Scaling Enterprise Conversational Intelligence: Cross-industry Technology and Functional Solutions Powered by Databricks Genie. The post catalogs more than forty partner accelerators across BI modernization, multi agent orchestration, observability, document processing and semantic layers. It lands twelve days before Data + AI Summit 2026 opens at Moscone on June 15, and it reads as the warm up for the keynote roadmap rather than a standalone product post.
Read in isolation, the piece looks like a partner marketing roundup. Read alongside the three other Databricks posts from the same week, Query Tags on June 2, the Liquid Clustering versus partitioning debunk on June 1 and the Iceberg v3 GA on May 28, it becomes one coordinated architectural argument. Genie is the surface. Iceberg v3 is the open table format. Liquid Clustering is the physical layout. Query Tags is the audit trail. Each piece on its own is incremental. Stacked, they describe a warehouse rebuilt for machine query patterns.
Genie as a research agent with the integration outsourced
The Genie post frames the product as a research agent that generates multi step plans and returns answers backed by verifiable lakehouse evidence. The more interesting detail is who is doing the building. Accenture, Cognizant, Deloitte, EY, Infosys, Tata Consultancy, Wipro and Persistent are listed alongside specialist shops like Tredence, MathCo, Tiger Analytics, Aimpoint Digital and Slalom. Databricks is openly delegating the integration surface to the systems integrator channel.
The numbers in the partner write ups are worth pulling out. Cognizant claims a semantic caching layer that cuts inference costs by 30 to 60 percent at 25,000 plus Genie calls. T1A says its Genie Forge accelerator reduces space setup time by 60 to 70 percent, saving 20 to 30 hours per space. Koantek compresses Genie space authoring from 10 to 15 days down to 3. EY claims a 60 percent reduction in manual loan document processing and 50 to 60 percent less debugging time on data quality rules. These are vendor numbers, but they are specific enough to test in a paid pilot.
The pattern matches what Snowflake is doing with Horizon Catalog and what Microsoft is doing with Fabric. The platform vendor ships the primitive, the SI channel productizes the deployment, and the enterprise pays twice. The choice in front of platform teams is whether to bring this in house or accept the partner tax.
Query Tags turns shared warehouses into attributable infrastructure
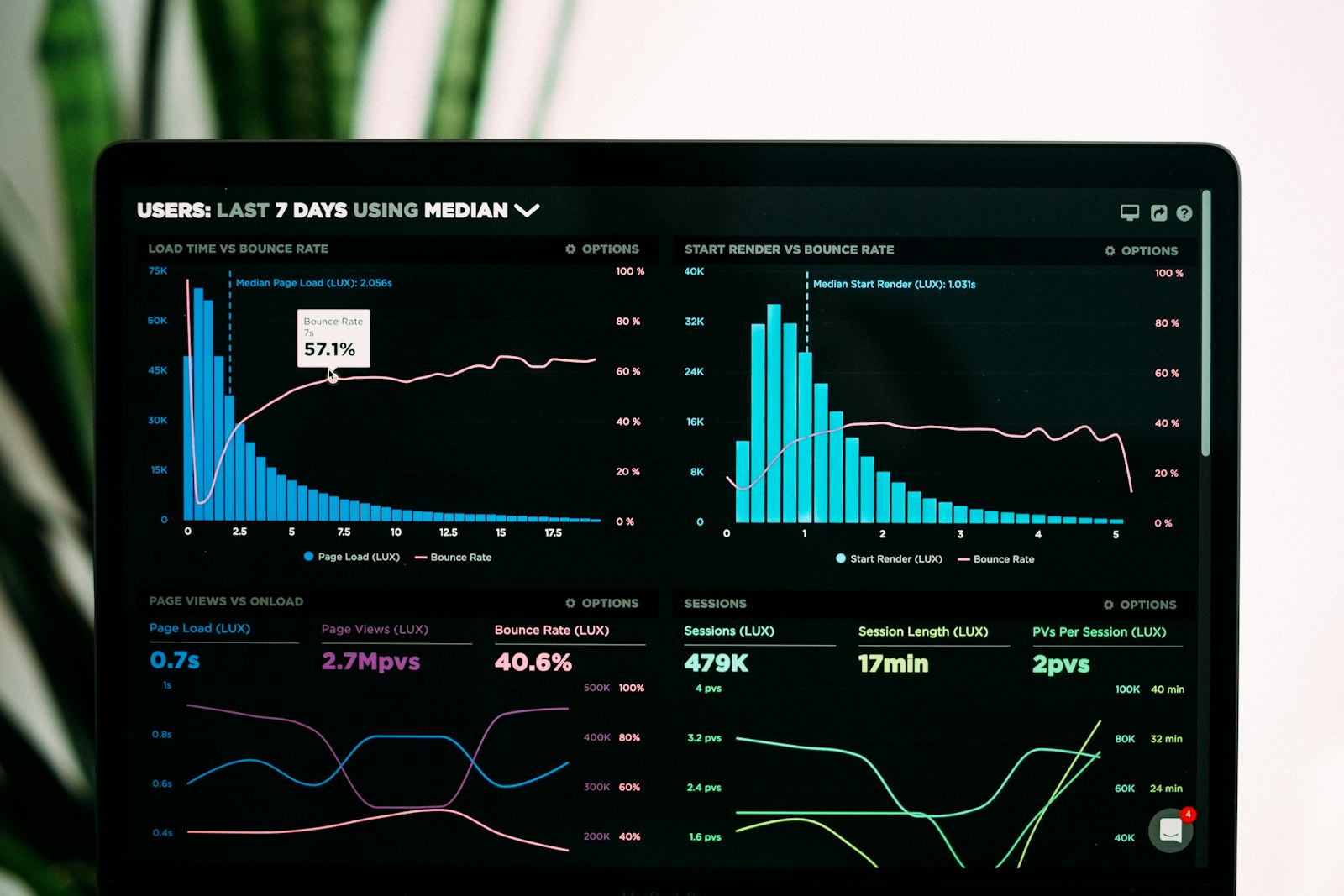
The Query Tags release is the most operationally significant of the four. Public preview on all clouds, attaches custom key value pairs to every SQL execution, lands in the Query History system table for chargeback and monitoring. dbt is auto tagged with model name, adapter version and materialization type at zero configuration. Power BI auto tagging of DatasetId and ReportId is opt in today and default in the next release. Tableau supports connection level tags with a tip to use the WorkbookName parameter so attribution survives renames.
The customer quotes are the tell. ASOS says it can now map every SQL workload to the originating dbt model without configuration. Unit21 says it consolidated from one warehouse per team to shared warehouses to cut costs, lost team level attribution in the process, and got it back through Query Tags from the Python connector. Both quotes describe the same operational problem, which is that shared warehouses are cheaper to run and harder to govern. Tags fix the governance side of that trade without forcing teams back onto isolated warehouses.
The agent angle is the reason this matters now. Warehouse queries from human analysts are bounded by working hours and curiosity. Queries from agents are bounded only by token budgets and orchestration loops. Without per query attribution, capacity planning for agent workloads is guesswork and chargeback is impossible. Query Tags is the instrumentation layer Databricks needs in place before agent traffic dominates the query mix.
Liquid Clustering and Iceberg v3 reshape the physical layer
The Liquid Clustering post is framed as eight myths to debunk, which in vendor language means stop following the guidance Databricks issued three years ago. The argument is that partitioning assumes predictable, low cardinality access patterns. Agent generated queries break those assumptions because they filter across more dimensions, generate higher cardinality predicates and produce skew that hot spots specific partitions. Liquid Clustering adapts the physical layout to actual query patterns. The recommendation is no longer optional for new tables in agent heavy workloads.
Iceberg v3 going GA with Open Sharing and Unified Governance closes the multi engine loop. Tables can be exposed to non Databricks consumers without copying, and the same Unity Catalog policy protects every reader. For organizations running Snowflake as primary warehouse and Databricks for ML, the copy and sync pattern that has defined the last three years of multi platform architecture is now technically obsolete. The political and licensing reasons to keep duplicating data have not gone away, but the technical excuse has.
What we are doing in the twelve days before Moscone
We are picking one production agent use case, a finance variance explainer running against the planning marts, and instrumenting it end to end. Query Tags goes on first because it is one line of SQL in the connector and the data lands in the query history table immediately. We are budgeting roughly forty engineering hours for the tag schema, dashboard and chargeback rollup. Pass cost for two platform engineers to attend the summit in person is 1,895 dollars each, and we are sending them with the brief to walk every partner booth listed in the Genie post and collect pricing on three accelerators, Cognizant on caching, T1A on space setup and Tredence on accuracy.
Liquid Clustering migration on the planning marts is the harder call. We are scoping a two week pilot on the three highest traffic tables, measuring query latency and storage cost delta against the current partition scheme. If the agent query latency improves by more than twenty percent at equal or lower storage cost, we migrate the rest of the marts in Q3. Iceberg v3 Open Sharing to our Snowflake footprint is the experiment we run after the summit, once the keynote has clarified whether Unity Catalog federation with Snowflake Horizon is a real interoperability story or a press release.
If the June 15 keynote ships a managed Genie evaluation harness or a first party answer to Snowflake Cortex Analyst pricing under one dollar per thousand queries, the buy versus build math on the partner accelerators shifts and we cancel two of the three vendor conversations. If it does not, we sign one accelerator contract before July 31 and move the second agent use case into pilot.