A Number So Large It Stops Meaning Anything
Twenty four billion is the kind of figure that numbs rather than alarms, which is exactly why it deserves a second look. On June 12, 2026, researchers at Cybernews found a publicly reachable Elasticsearch cluster holding 24 billion credential records spread across 8.3 terabytes of data. There was no password on it, no authentication layer, nothing between the records and anyone who knew where to point a browser. The database stayed open until June 15, when it was finally pulled offline. In those few days, anyone could have copied the entire thing.
We have learned to discount these headline figures because the records are usually stale, duplicated, or recycled from breaches everyone already mitigated years ago. That instinct is healthy. But it fails here, and the reason it fails is the part of this story that should worry every CISO. The composition of the data, and crucially the way it was being maintained, turns a scary number into an operational threat. This was not a museum of old passwords. It was a working tool, and it was being kept current.
Where 24 Billion Records Come From
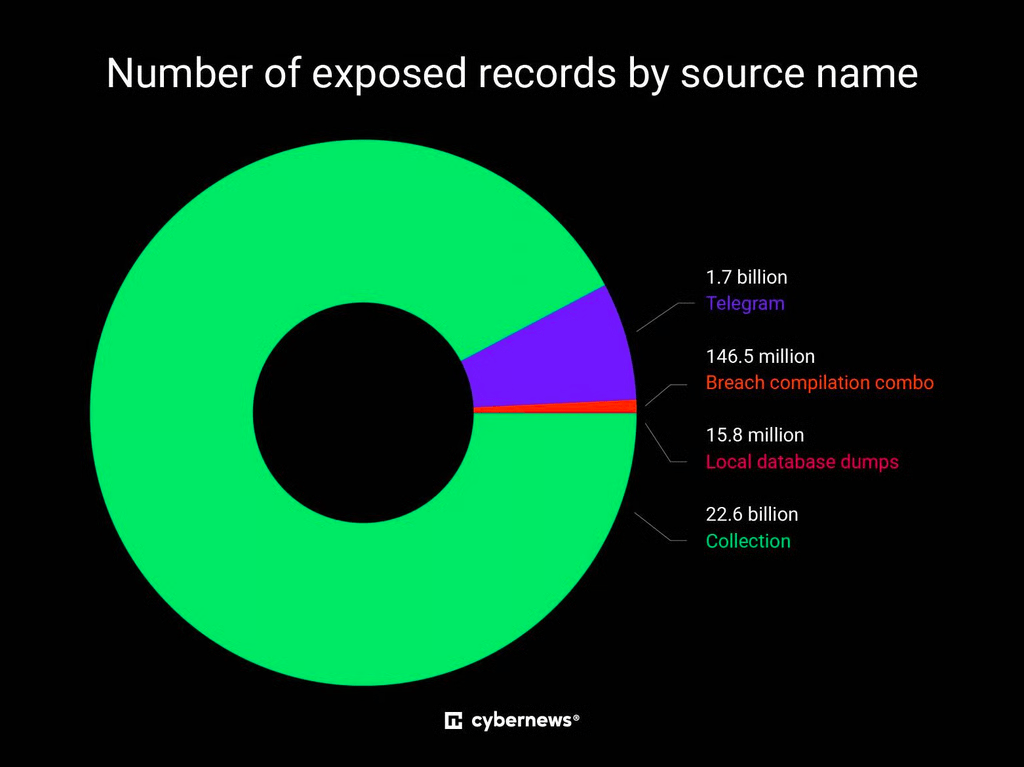
Cybernews traced the contents to 36 distinct sources. Roughly 1.7 billion records came from hacking-related Telegram channels, predominantly English and Russian, including at least one channel focused on stolen credit card data and a cluster the researchers labeled Darkside that contributed around 260 million records. The remaining bulk, some 22.6 billion records, was tagged as collections: breach compilation combos, local database dumps, and enormous aggregations of infostealer logs harvested from infected machines around the world.
The detail that matters for defenders is format. The vast majority of the records were structured infostealer logs, meaning each entry pairs a username or email address with a plaintext password and the specific login URL that credential unlocks. That is not a haystack you have to search. It is a sorted index. An attacker does not need to guess which service a password belongs to, because the log already says so. The dataset even contained roughly 17,000 records tagged with CVE identifiers and several thousand logs of news articles and social posts about breaches, suggesting the operator was enriching credentials with vulnerability context.
The Owner Was a Threat Intelligence Firm
At first the researchers could not identify who owned the cluster. That uncertainty resolved into something more uncomfortable. The team eventually concluded the data belonged to a threat intelligence company, the kind of vendor that aggregates leaked credentials precisely so it can warn customers when their accounts surface. The irony is brutal: an organization whose entire business is protecting people from exposed credentials left 24 billion of them exposed on the open internet.
There was also evidence the cluster was alive rather than archived. The researchers noted that a news article from February 2026 sat inside the leak, which told them the owner was regularly updating the database with fresh material. That single observation changes the risk calculus entirely. A static dump degrades in value as victims rotate passwords. A continuously refreshed dump does not. It tracks the current state of credential exposure across the internet, which means a meaningful share of those records still works right now.
Why This Is a Credential Stuffing Engine
The practical danger is not that 24 billion people each lost a password. It is that the aggregation hands attackers a ready-made input for credential stuffing and account takeover at industrial scale. Feed those username and password pairs into automation, point it at corporate single sign-on portals, VPN gateways, and SaaS logins, and a small success rate against a huge input still yields thousands of working sessions. Reused passwords are the vulnerability, and this dataset is essentially a global map of where reuse exists.
The standard advice applies, but the urgency does not. Multi-factor authentication remains the single most effective control, because a stolen password is worthless against a phishing-resistant second factor. Cybernews was blunt that accounts without MFA are at serious risk of takeover. The harder problem is the infostealer pipeline feeding this thing. Credentials end up in these logs because malware sits on an employee's machine and scrapes the browser. Resetting passwords does nothing if the device is still infected, which is why endpoint hygiene has to be part of the response, not an afterthought.
What Enterprises Should Do This Week
Assume exposure rather than hoping for the opposite. Treat any workforce or customer account that lacks phishing-resistant MFA as already compromised and prioritize rolling out hardware keys or passkeys to the highest-value identities first. Force password resets where you cannot yet enforce a second factor, and run your corporate domains through breach monitoring so you can see which employee credentials are circulating. Tune your authentication logs to flag the signature of credential stuffing: bursts of failed logins across many accounts from rotating addresses.
The deeper lesson is about supply chain trust in security itself. A threat intelligence vendor sitting on 8.3 terabytes of plaintext credentials with no authentication is a reminder that the firms you rely on to monitor exposure can become the exposure. When you evaluate these vendors, ask hard questions about how they store the data they collect on your behalf. The 24 billion figure will fade from headlines within days. The credential reuse it exploits will not, and neither will the appetite of attackers who now have a cleaner shopping list than they have ever had before.


