A Cache Learns to Remember
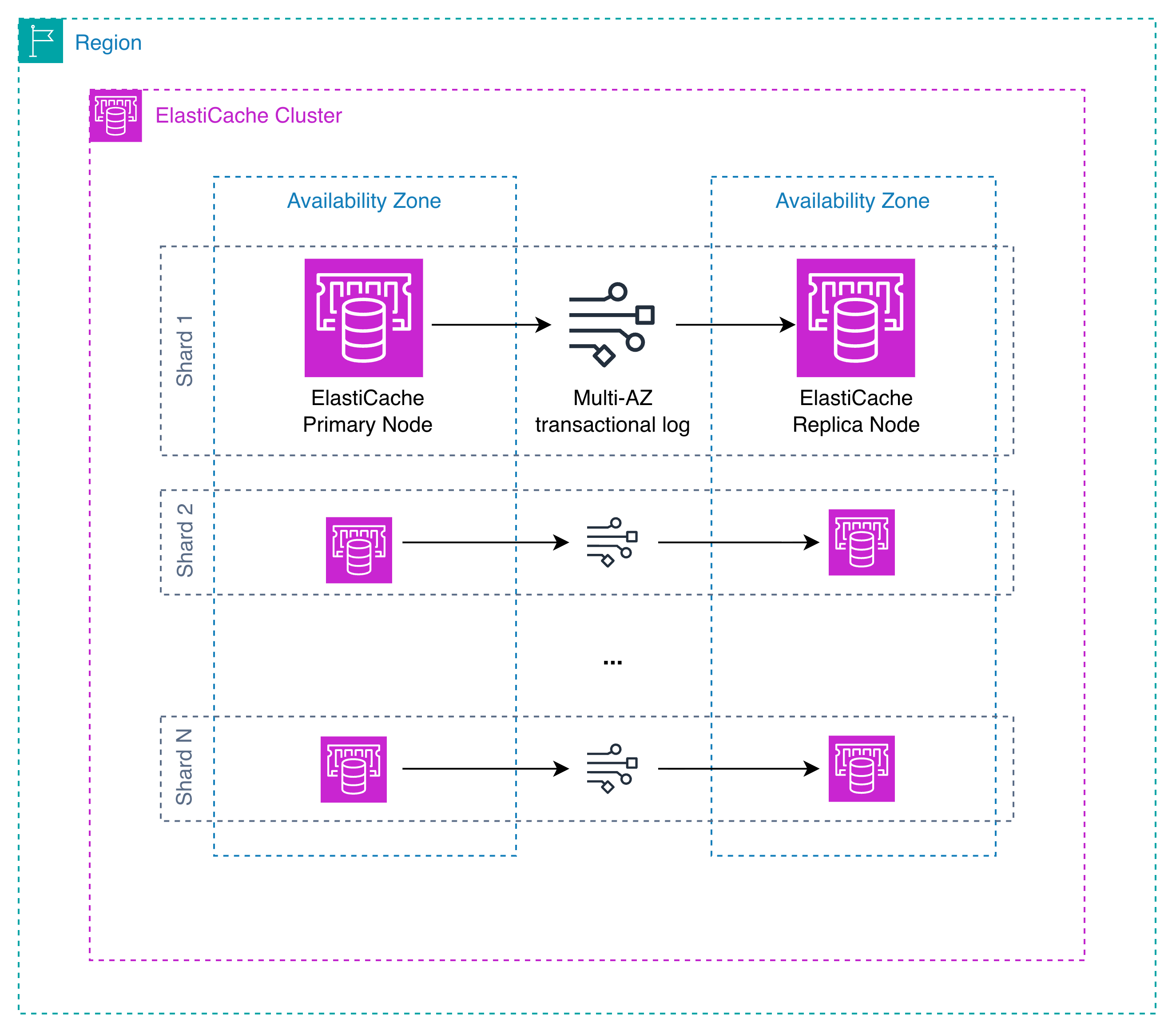
Amazon Web Services has added a durable storage option to ElastiCache for Valkey, and the move is more consequential than the routine feature note that accompanied it. For most of its life, ElastiCache has been exactly what its name promises: a fast, ephemeral cache that sits in front of a system of record and accepts that, in a failure, some of its contents simply vanish. The new durability tier changes that contract. Writes can now be committed to a Multi-AZ transactional log before they are acknowledged, which means an acknowledged write survives a node failure, a restart, or an Availability Zone outage. AWS frames the change around a single sentence that explains the whole strategy.
"Many organizations find that Multi-AZ replication and automatic failover in ElastiCache meet their resilience requirements, but as customers increasingly adopt ElastiCache as a persistent data store, as well as a cache, data loss becomes a primary concern," wrote AWS engineers Jules Lasarte and Karthik Konaparthi. That phrase, persistent data store, is the tell. Teams have been quietly using Valkey and its Redis lineage for far more than caching for years. AWS is now meeting that reality with a supported durability guarantee rather than leaving it to chance and clever client-side workarounds.
Two Modes, Two Trade-Offs
The durability feature ships in two flavors, and the difference between them is the whole point. Synchronous durability commits a write only after the data has been recorded in the transactional log across at least two Availability Zones. AWS describes the result plainly: "Every acknowledged write is durable, and write latency is single-digit milliseconds." For workloads that cannot tolerate losing a confirmed write, that is the configuration to reach for, and read latency stays at the microsecond level customers expect from an in-memory store.
Asynchronous durability takes the opposite stance. It acknowledges writes before replication completes, preserving the lowest possible write latency at the cost of a bounded window of risk. AWS is candid that "up to 10 seconds of uncommitted data can be lost in the unlikely event of a failure," and a durability buffer enforces that ceiling by temporarily rejecting writes if replication lag grows past the limit. The honesty matters here. Rather than pretending durability is free, AWS is forcing architects to name the trade-off they are actually willing to make.
Why AI Workloads Are Driving This
The timing is not accidental. AWS explicitly calls out AI agent memory, retrieval-augmented generation knowledge bases, and session storage as motivating use cases. These are workloads where the data living in the fast tier is not a disposable copy of something safely stored elsewhere; it is often the authoritative state of an ongoing interaction. An agent's working memory, a session's accumulated context, or a freshly computed embedding can be expensive or impossible to reconstruct if it disappears. Durability turns a cache into a credible home for that kind of state.
This is the strategic subtext of the announcement. As enterprises wire AI agents into production, they keep discovering that the boundary between cache and database is exactly where their hardest reliability questions live. By giving Valkey a durability dial, AWS lets teams keep microsecond reads while choosing precisely how much write safety they need. That is an attractive proposition for organizations that would otherwise stand up a second, slower system of record purely to avoid losing agent state, and it consolidates infrastructure that was drifting toward duplication.
The Industry's Standing Warning
Not everyone is celebrating without caveats, and the most useful reaction came from a skeptic. Cloud economist Corey Quinn of The Duckbill Group offered a characteristically blunt reminder: "Once again I am begging you to not confuse 'cache' with 'primary data store.'" The point is well taken. Durability options make ElastiCache capable of holding important data, but capability is not the same as wisdom. A bounded ten-second loss window or even single-digit-millisecond synchronous writes may be perfectly acceptable for agent memory and entirely unacceptable for financial ledgers.
The risk we see is that durability features blur a distinction that engineering teams have historically been forced to respect. When a cache can be configured to never lose acknowledged writes, the temptation to treat it as the system of record grows, and so does the chance of an architecture that nobody fully reasoned about. The right reading of this release is narrower and healthier: ElastiCache for Valkey now spans a wider band of the latency-durability spectrum, and the responsibility for choosing the right point on that spectrum sits squarely with the architect.
What CTOs Should Take Away
For technology leaders, the practical implication is a consolidation opportunity worth examining. Teams that have been running a fast cache plus a separate durable store solely to protect session or agent state may now be able to collapse that into one Valkey deployment with synchronous durability, available across all commercial Regions, AWS China Regions, and GovCloud starting with Valkey 9.0. Fewer moving parts means fewer failure modes and lower operational overhead, provided the durability mode is chosen deliberately rather than by default.
The broader signal is about where in-memory data platforms are heading. Valkey, the community fork that emerged after Redis changed its license, is accumulating exactly the enterprise-grade guarantees that make it viable for serious production state, and AWS is investing in it as a first-class persistence layer rather than a disposable accelerator. We expect competing managed offerings to follow, because the demand is coming from AI architectures that need fast, durable, and governed state in the same place. The cache that remembers is no longer a contradiction; it is becoming a category.


