Context Windows Are Not Memory
The reflexive answer to giving an AI agent memory has been to make the context window bigger and stuff more history into it. Elastic's new open-source project, Atlas, released on June 30, is a direct rejection of that approach. Built on Elasticsearch and integrated with agents through the Model Context Protocol, Atlas is a long-term, persistent memory store that outlives a chat session, scales to years of interaction data, and lets an agent fetch facts filtered by content, time, and user. The pitch, in Elastic's words, is uncompromising: "A 1M-token context window is a scratchpad. It is not a memory system."
We think that line is more than a slogan. Elastic argues the naive approach breaks down on cost, on latency, and on the well-documented lost-in-the-middle effect, where models fail to attend to information buried deep in a long prompt. For any team that has watched an agent's bill and latency balloon as conversations grow, the diagnosis is familiar. What Atlas offers is a structured alternative to the brute-force context stuffing that most agent frameworks still treat as the default, and it comes with source code on GitHub rather than a whitepaper and a waitlist.
Three Kinds of Memory, Three Indices
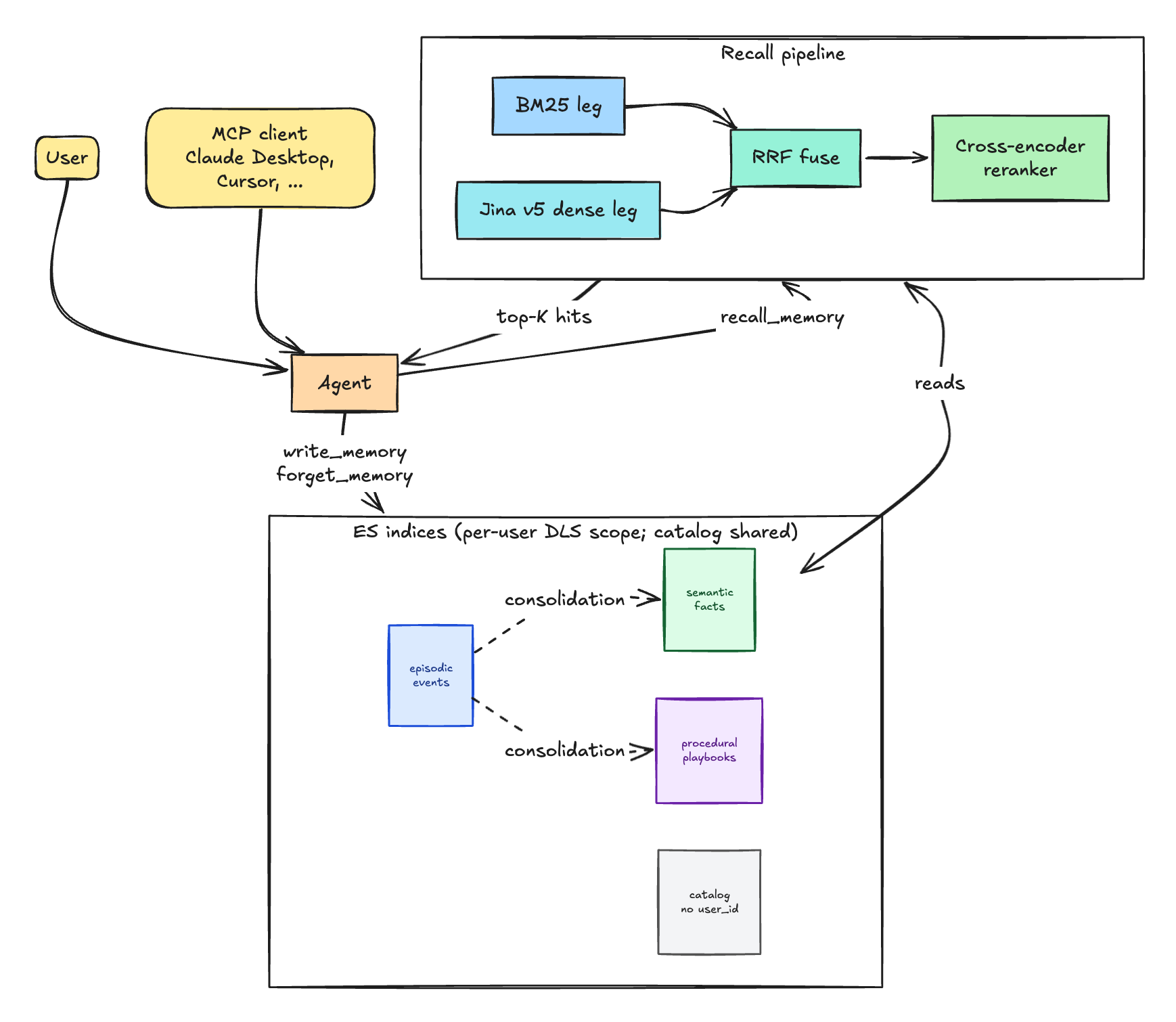
The core design idea is that memory is not uniform. Atlas mirrors human cognitive science by splitting memory into three categories, each in its own Elasticsearch index with its own lifecycle: episodic memory for what happened, semantic memory for what is true, and procedural memory for what works. Elastic's reasoning is that these behave differently. As author Noam Schwartz put it, "events the user lived, stable facts about them, and step-by-step playbooks all have different write rates and aging rules." An event should decay over time, a stable fact should persist, and a working playbook should be reinforced when it succeeds.
Separating them is an engineering choice with real consequences. Different indices mean different retention, supersession, and decay policies, so a superseded fact can be retired without disturbing the record of what happened, and a proven procedure can be promoted independently. This is the kind of distinction that gets lost when everything is dumped into a single vector store and retrieved by similarity alone. By modeling the lifecycle explicitly, Atlas turns memory management into a set of policies rather than an emergent accident of how embeddings happen to cluster.
Why Elasticsearch Instead of a Vector Database
The choice of Elasticsearch over a dedicated vector database is the most opinionated decision in the project, and Elastic does not hide that it makes the search company. Schwartz framed the requirements first and the tool second: "The requirements describe a search engine, so this implementation uses one." The argument is that agent memory needs far more than nearest-neighbor vector lookup. It needs lexical filtering, time ranges, per-user constraints, scripted scoring, and reranking, all of which a mature search engine already provides out of the box.
The wider community made a similar point. One Hacker News commenter noted that "'any other vector DB' starts to fall apart once you need stuff like scripted scoring," after which the question becomes whether you even need approximate nearest neighbor for performance at all. We read this as a healthy corrective to two years of vector-database hype. For many real agent workloads, the hard part is not similarity search, it is combining similarity with structured filters and business rules, and that is exactly the territory search engines have owned for a decade.
Hybrid Retrieval and the Reranker
Under the hood, Atlas does not rely on embeddings alone. Retrieval uses Reciprocal Rank Fusion to combine BM25 lexical search with Jina v5 semantic search, then passes the merged results through a cross-encoder reranker before handing context back to the agent. The lexical layer catches exact terms and identifiers that embeddings often blur, the semantic layer catches paraphrase and intent, and the reranker sharpens the final ordering so the agent sees the most relevant memories first. Recall on a question-answering evaluation reached 0.89 Recall@10, a respectable figure for a system meant to run against years of history.
This hybrid design is where the search-engine bet pays off in practice. Fusing lexical and semantic signals is difficult to bolt onto a pure vector store, but it is native to Elasticsearch, and the reranking step is the difference between retrieving something plausible and retrieving something correct. For engineering teams, the lesson is that agent memory quality is a retrieval problem first and a storage problem second. The embedding model matters, but the fusion and reranking strategy around it often matters more, and Atlas makes that layer explicit rather than hiding it.
Per-User Isolation and the Enterprise Angle
Memory that spans years of user history is a privacy and compliance liability the moment it crosses tenant boundaries. Atlas addresses this with document-level security to enforce per-user memory isolation, so an agent retrieving context for one user cannot surface another user's episodic events or facts. In a multi-tenant enterprise deployment, this is not a nice-to-have, it is the line between a useful memory system and a data-leak incident waiting to happen. Building it on Elasticsearch means the isolation rides on an access-control model that already exists and is already audited in production.
We see this as the detail that makes Atlas interesting to enterprise buyers rather than just hobbyists. Plenty of agent-memory demos work beautifully for a single user and quietly ignore what happens when thousands share the store. By putting isolation at the document-security layer from the start, Elastic is signaling that it built Atlas for the kind of deployment where a regulator might one day ask who could read what. That framing, more than the recall score, is what could move this from a GitHub curiosity into a real building block.
What It Means for Teams Building Agents
Atlas ships as open source, with a demo implementation and documentation on GitHub, which lowers the barrier for teams to try the pattern rather than buy a product. That is a shrewd move by Elastic. The company gets to define what good agent memory looks like, and if the pattern catches on, the most natural place to run it is on Elasticsearch. It is open-source advocacy and product strategy at the same time, and both readings are fair.
For engineering leaders, the value here is less the specific code and more the architecture it argues for. Model memory as three lifecycles rather than one blob, retrieve with hybrid search and a reranker rather than raw vector similarity, and enforce isolation at the data layer. Those principles hold whether or not you adopt Atlas itself. In a market still reaching for bigger context windows as the answer to every memory question, a credible, opinionated, open counterexample is worth paying attention to.